





导语:传统数据存储架构在支撑大模型快速迭代升级过程中暴露出承载瓶颈,以AI原生存储为代表的新型AI存储具备超高性能、超大容量、极致安全、数据编织等特征,可以有效支撑大模型数据归集、预处理、训练、推理等全生命周期流程。

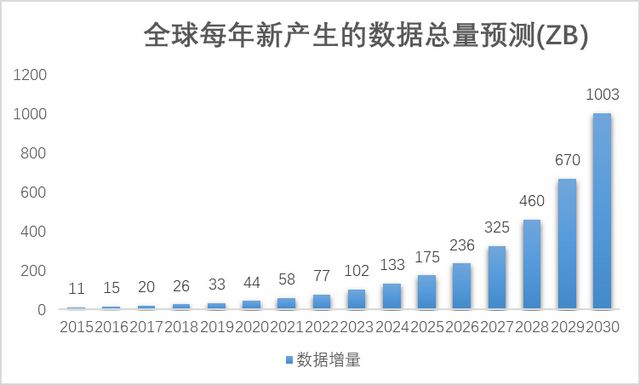
伴随人工智能大模型的高速发展,数据量呈指数级增长,存储产业迎来新一轮的增长。根据IDC和华为GIV团队预测,全球每年新产生的数据总量随着AI的发展快速增长,从2020年每年产生2ZB到2025年每年产生175ZB,2030年将达到1,003ZB,即将进入YB时代[1]。
在数据采集与清洗环节,由于原始数据规模大、来源多样、种类丰富,需要构建大容量、低成本、高可靠的数据存储底座,并且用标准文件的方式完成海量数据的清洗和转换,以缩短数据预处理的时长。
在模型训练与推理应用环节,由于主流预训练模型训练过程不稳定,需要用Checkpoint(检查点)机制来确保训练回退到还原点,因此,要求存储能快速读写Checkpoint文件。
此外,为保证大模型生成的内容是合法、合规的,存储需要提供比较丰富的数据审核能力。
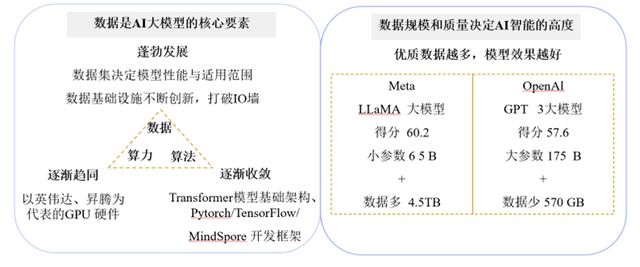
同时,各企业采用的算力、算法逐渐收敛,数据成为真正体现大模型差异性的关键要素。训练数据的体量与质量对提升大模型的效果具有显著作用。尽管LLaMA3的参数规模不到GPT-3.5的一半,但其15TB训练数据远超GPT-3.5的570GB训练数据,使其在大部分基准上均表现更优[2]。
传统数据存储架构在支撑大模型快速迭代升级过程中暴露出显著瓶颈,已难以承载世界级认知系统的数据需求。
首先,传统存储系统的吞吐性能与并发能力难以匹配GPU算力需求,IO延迟导致算力空转现象普遍;其次,面对大量非结构化数据,传统方案极易出现孤岛与重复拷贝的问题,缺失元数据追溯与可复现性机制;再者,冷热数据分层依赖人工,存在误判风险,影响训练效率;此外,对象存储在AI训练场景中暴露高并发读写短板,多存储系统拼接导致数据频繁搬运与格式冲突。
以AI原生存储为代表的新型AI存储是专为人工智能应用和服务设计的数据存储系统,具备超高性能、超大容量、极致安全、数据编织等特征,可以有效支撑大模型数据归集、预处理、训练、推理等全生命周期流程,正成为破局的关键。

AI原生存储(AI-Native Storage)是指为AI系统尤其是大模型训练、推理、数据治理等工作负载量身定制的下一代智能存储系统,其架构、性能、接口、调度、元数据系统等各方面都以AI应用的需求为核心设计,而非对传统存储系统的简单改造。
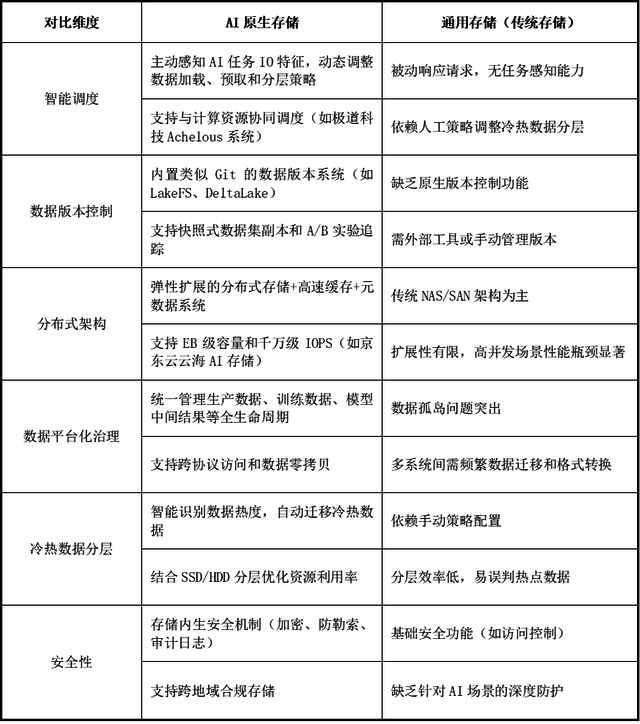
AI原生存储与通用存储(传统存储)在架构设计和功能特性上存在显著差异,主要面向AI大模型训练和推理场景的特定需求,在智能调度、数据版本控制、组成架构、数据治理、数据分层、安全性等方面进行优化。
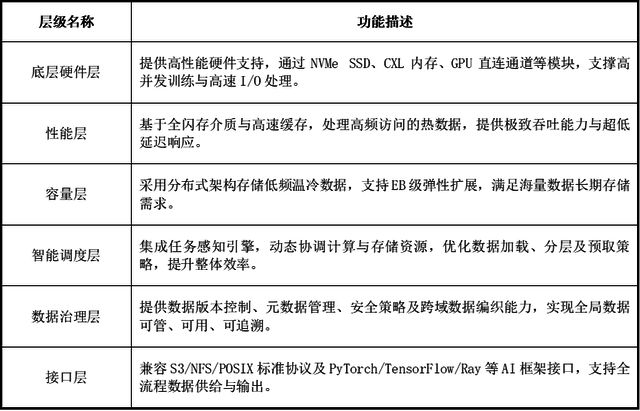
AI原生存储(AI-Native Storage)涵盖底层硬件、性能、容量、调度、数据治理、输出输入接口等各层级,提升大模型数据存储能力。
AI原生存储体系在应对大模型商用化挑战时,逐步形成了多维度协同的架构范式,成为AI基础设施中主动参与任务调度的“神经中枢”,主要包括分布式文件系统架构、对象存储架构、混合存储架与并行文件系统架。
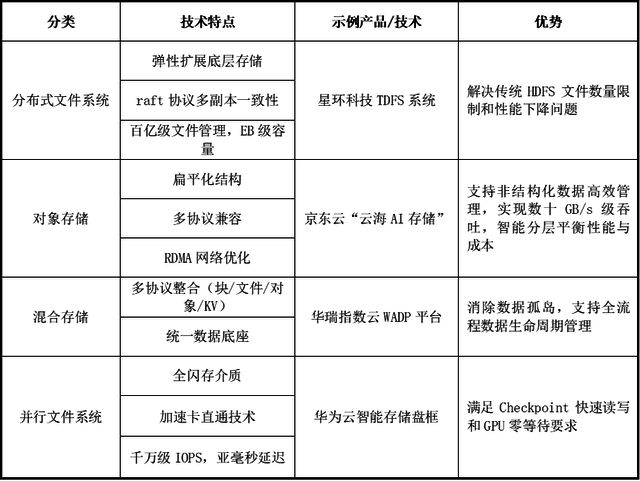
为确保不同的数据形态维度在训练、推理及知识库构建中的高效流动与智能调度,针对不同数据形态维度,AI原生存储体系可分为结构化数据存储、非结构化数据存储及多模态数据存储。
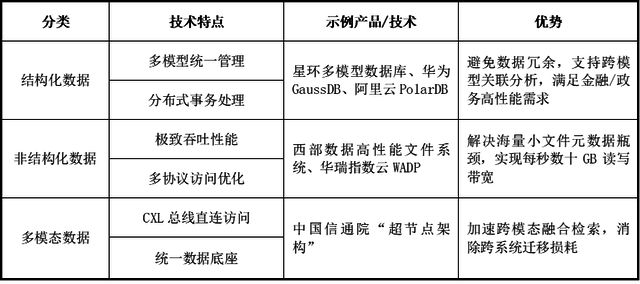
不同的工作负载维度各有其独特的需求和特点,对应的AI原生存储中包括训练型存储、推理型存储和采集预处理型存储。
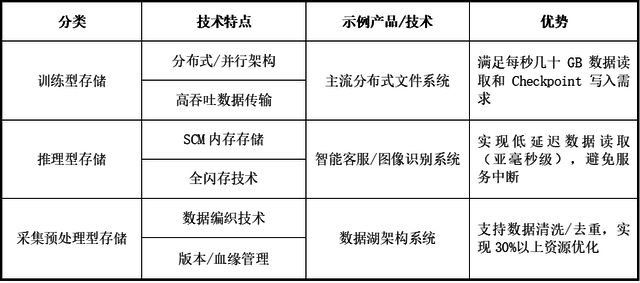
基于感知能力维度,存储体系可分为被动型传统存储、智能型存储、与自学习型存储。传统存储系统主要遵循“被动响应”的模式,在面对AI应用中复杂多变的数据访问模式和性能需求时,往往显得力不从心,更适用于AI大模型领域的是智能型存储、与自学习型存储。
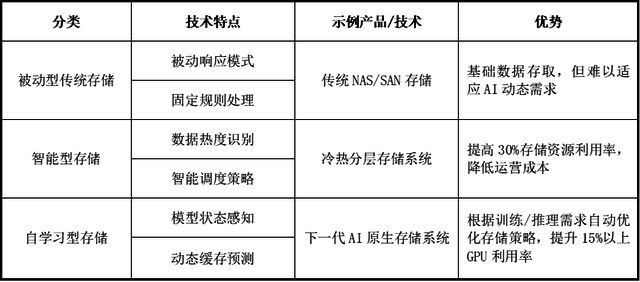

传统存储阶段主要采用集中式设计,数据存储和处理高度依赖于中心化硬件设备,如存储区域网络(SAN)和网络附加存储(NAS)。这类架构通过专用硬件(如高端磁盘阵列)和封闭协议(如光纤通道)实现数据集中管理,虽能提供较高的单点性能和可靠性,但存在显著局限性。
其扩展性受限于硬件设备的物理容量,无法弹性应对数据量激增;存储与计算紧耦合的设计导致资源利用率低下,尤其在处理海量非结构化数据时易出现性能瓶颈。此外,集中式架构存在单点故障风险,容灾能力较弱,且依赖昂贵专有硬件,维护成本高昂。
随着数据规模指数级增长及AI等新场景对高并发、低延时的需求,传统架构在吞吐能力、成本效益和灵活性上的不足日益凸显,逐渐被分布式存储架构取代。
需求驱动下的探索阶段是随着数据量的爆发式增长和技术革新推动的必然产物。在全球及中国数据产量持续攀升的背景下(2023年达32.85ZB)[3],数据资源呈现出海量规模、多样类型、低价值密度和高速流转的“4V”特性,传统集中式关系型数据库在处理半结构化/非结构化数据时遭遇严重瓶颈。
生成式人工智能与大模型技术的突破进一步提升了数据存储的刚性需求,倒逼技术变革。这一阶段的核心特征体现为从“关系型、集中式”向“非关系型、分布式”的范式转移,并逐步向“多模型、云原生”深化演进。通过存算分离、资源池化等技术重构数据管理架构,云原生数据库的私有化部署模式因满足“数据不外流”的安全需求而快速崛起。
与此同时,多模型数据管理系统应运而生,支持结构化、图数据、文档等多类型数据的融合处理,显著降低跨模型数据联合处理的架构复杂度与运维成本。这一阶段的技术探索为后续AI原生存储体系的形成奠定了基础,标志着数据管理软件从被动适配向主动创新的关键转折。
随着大模型技术快速发展,在AI从科研范式转向工业级应用的过程中,传统存储架构面临多模态数据管理、海量版本控制、实时推理支持等核心挑战,促使存储系统从被动数据仓库向主动智能中枢转型。
这一体系形成的关键在于存储技术与AI任务需求的深度耦合:初期通过分布式架构突破性能瓶颈,实现EB级扩展和千万级IOPS;中期引入智能调度引擎,使存储系统能感知训练任务特征,动态优化数据预取和分层策略;后期深度融合数据编织技术,构建跨域数据湖并实现全生命周期治理。
随着LakeFS、DeltaLake等数据版本系统的普及,以及KVCache持久化、RAG知识库等新型存储形态的出现,存储系统逐渐具备任务感知、算法协同能力,形成存算一体的智能数据供应链。
云厂商和头部企业通过自研调度引擎、统一存储底座等实践,推动存储从基础设施升维为AI系统的神经中枢,最终实现数据不动模型动、推理即取即用的新一代范式,为AI应用提供高效、安全、自主可控的数据支撑。

自2021年以来,中国在AI数据存储及先进存储领域陆续出台了一系列扶持政策,涵盖国家层面顶层设计与地方政府的具体实施方案,涉及数据存储基础设施建设、智能算力调度、数据安全合规、关键核心技术突破等多个方向。
这些政策文件不仅体现在《“十四五”数字经济发展规划》《国家信息化规划》《算力基础设施发展行动计划》等国家级战略中,也延伸至深圳、上海、北京等地在算力中心布局、智能数据湖建设、AI原生存储场景落地方面的专项支持。
整体来看,政策导向呈现出“重基础设施、强安全管理、促产业融合”的特征,体现出中国政府对AI数据存储关键地位的高度认可。其核心目标是通过政策牵引、资金扶持与资源配置,推动形成安全可控、高性能、高效率的数据存储能力体系,为人工智能大模型、AIGC、长记忆Agent等新兴应用提供坚实底座,加快建设数字中国。
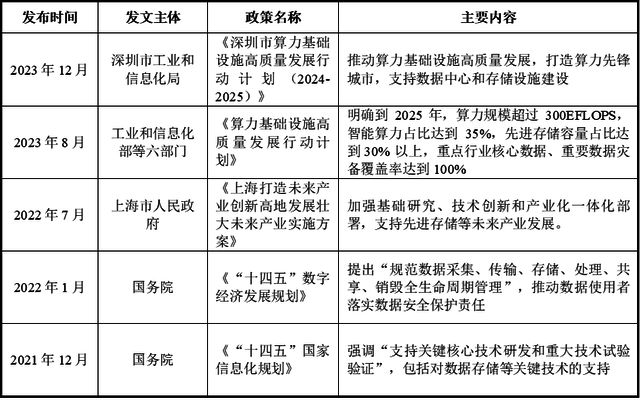

软硬件一体化销售模式(Appliance Model)是存储领域中一种典型的商业交付方式,其核心在于企业将自主研发的AI原生存储软件与经过深度优化和预配置的硬件设备(如高性能服务器、NVMeSSD、高速网络接口卡等)打包成完整的一体机系统,作为“交钥匙”解决方案直接销售给客户。
该模式的典型代表包括DDN的AI400X、华为OceanStorPacific系列、浪潮HFSS系列等。这类产品通常面向大型智算中心、AI科研平台、大型科技企业等客户群体,单次合同金额较高,交付复杂度大,但也带来了强客户粘性和稳定的后续服务收益。
对厂商而言,软硬一体化不仅有助于控制整体系统性能边界,还能增强产品的差异化竞争力,构建深度绑定的行业解决方案生态。
软件授权订阅模式(Subscription Licensing)的基本形式是将AI原生存储系统作为一款独立的软件产品授权给客户使用,客户根据使用周期(如年、季度、月)或使用资源量(如存储容量、并发节点数、IO带宽等)支付订阅费用,从而获得该软件的合法使用权以及持续更新、技术支持和版本升级等服务。
订阅授权模式强调“持续价值交付”,使厂商可以通过不断迭代优化产品、增加新功能和适配更多AI场景来保持客户粘性。典型厂商如WEKA、VASTData、国内的杉岩数据、星辰天合等。
订阅模式不仅有助于降低客户初期采购门槛,也让厂商获得可持续的现金流和用户反馈,支撑其在AI时代不断演进的产品策略。
托管云服务模式(Managed Cloud Service)是通过云平台将其存储能力以服务的形式交付给客户的一种商业模式。该种模式下,用户可以通过API或控制台快速申请存储资源,并根据实际业务需求进行动态扩容或缩容。
与本地部署或私有化部署不同,这种模式的核心理念是“即开即用、按需计费、弹性扩展”,客户无需采购硬件或自行搭建复杂的存储系统,而是通过公有云、私有云或混合云平台直接访问和使用厂商提供的AI原生存储服务,计费方式通常包括按存储容量、访问频率(如Get/Put请求数)、带宽流量、并发连接数等维度进行精细化计费。
这种服务通常以对象存储、文件系统或高性能并行存储的形式提供,支持高吞吐、低延迟、高并发等AI模型训练和推理所需的关键能力。典型提供者包括如WEKA在AWS/GCP上的云原生版本、VASTData的UniversalStorage云服务版本,以及国内的华为云FusionStorage、阿里云PanguStorage等。
项目定制部署模式(Project-based Custom Deployment)是针对特定行业客户或大型项目需求,提供定制化解决方案,包括从存储系统架构设计、软硬件选型、接口适配、性能优化,以及到现场部署、运维体系建设、人员培训等多个环节。
该模式通常发生在政企单位、智算中心、科研院所、大型国有企业等场景中,以“项目合同制”进行商务交付,项目金额高、交付周期长,客户粘性强。例如,某政务大模型项目需要支持跨区域多中心的数据共享与异地灾备,厂商可能会提供多副本容灾结构、AI任务调度感知存储分层机制、统一运维平台等专属功能,并针对客户原有系统进行接口对接和兼容适配。
典型厂商如华为、浪潮信息,以及部分国产AI原生存储新锐企业(如杉岩数据、星辰天合)均积极尝试这种模式在智算中心、科研院校和关键行业客户中建立深度合作关系。
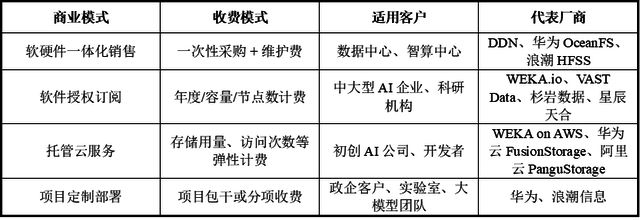

AI原生存储行业的上游主要包括存储介质与存储器、存储主控芯片与接口芯片、关键材料与零部件以及核心专利与技术。
中游参与者主要是各大AI存储系统综合解决方案提供商,包括软件平台,硬件基础设施集成以及综合云平台。
随着人工智能技术的快速发展,尤其是在大模型、AIGC(生成式人工智能)等新兴应用的推动下,传统存储系统已难以满足AI对海量数据的高并发访问、高吞吐率与低延迟处理的需求。
在这一背景下,AI原生存储作为专为AI工作负载设计的新型存储架构,正在成为行业关注的焦点,市场需求正随着数据规模的爆炸式增长而迅速扩大。
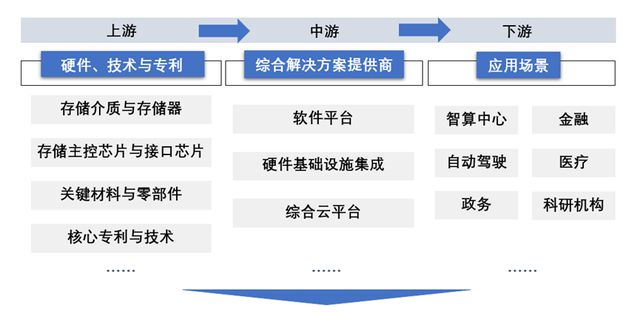
2024年,全球AI原生存储行业的市场规模为8.47亿美元,预计至2028年全球AI原生存储行业的市场规模增长至132.80亿美元。
在“AI+”国家战略持续推进下,中国AI产业快速发展,带动对数据存储能力提出前所未有的需求。与欧美相比,中国在AI训练数据量的生成速度和模型应用的广度上具备独特优势,AI原生存储因此成为国产化技术突围的重要方向。
头部云厂商、存储设备制造商与AI基础设施服务商正在加速布局,推动形成涵盖自研硬件、智能软件、异构计算适配与高效数据调度的完整生态。随着AI模型的参数量、推理密度与多模态应用的不断升级,中国AI原生存储市场正步入高速成长期,成为全球市场中最具活力的增长引擎之一。
2024年,中国AI原生存储行业的市场规模为14.36亿元,同比增长逾2倍,预计至2028年市场规模增长至224.32亿元。


