





EMR Serverless Spark 免费试用,1000 CU*H 有效期3个月
EMR Serverless StarRocks,5000CU*H 48000GB*H
JindoFS 是一套新的云原生的数据湖解决方案。在 JindoFS 之前,云上客户主要使用 HDFS 和 OSS/S3 作为大数据存储。HDFS 是 Hadoop 原生的存储系统,10 年来,HDFS 已经成为大数据生态的存储标准,但是我们也可以看到 HDFS 虽然不断优化,但是 JVM 的瓶颈也始终无法突破。
在 JindoFS 之前,云上客户主要使用 HDFS 和 OSS/S3 作为大数据存储。HDFS 是 Hadoop 原生的存储系统,10 年来,HDFS已经成为大数据生态的存储标准,但是我们也可以看到 HDFS 虽然不断优化,但是 JVM 的瓶颈也始终无法突破,社区后来重新设计了 OZone。OSS/S3 作为云上对象存储的代表,也在大数据生态进行了适配,但是由于对象存储设计上的特点,元数据相关操作无法达到 HDFS 一样的效率;对象存储给客户的带宽不断增加,但是也是有限的,一些时候较难完全满足用户大数据使用上的需求。
EMR Jindo 是阿里云基于Apache Spark / Apache Hadoop在云上定制的分布式计算和存储引擎。Jindo 原是内部的研发代号,取自筋斗(云)的谐音,EMR Jindo在开源基础上做了大量优化和扩展,深度集成和连接了众多阿里云基础服务。阿里云EMR (E-MapReduce)在 TPC 官方提交的 TPCDS 成绩,也是使用 Jindo 提交的。
EMR Jindo 有计算和存储两大部分,存储的部分叫 JindoFS。JindoFS 是阿里云针对云上存储定制的自研大数据存储服务,完全兼容 Hadoop 文件系统接口,给客户带来更加灵活、高效的计算存储方案,目前已验证支持阿里云 EMR 中所有的计算服务和引擎:Spark、Flink、Hive、MapReduce、Presto、Impala 等。Jindo FS 有两种使用模式,块存储模式和缓存模式。下面我们来分析下,JindoFS 是如何来解决大数据上的存储问题的。
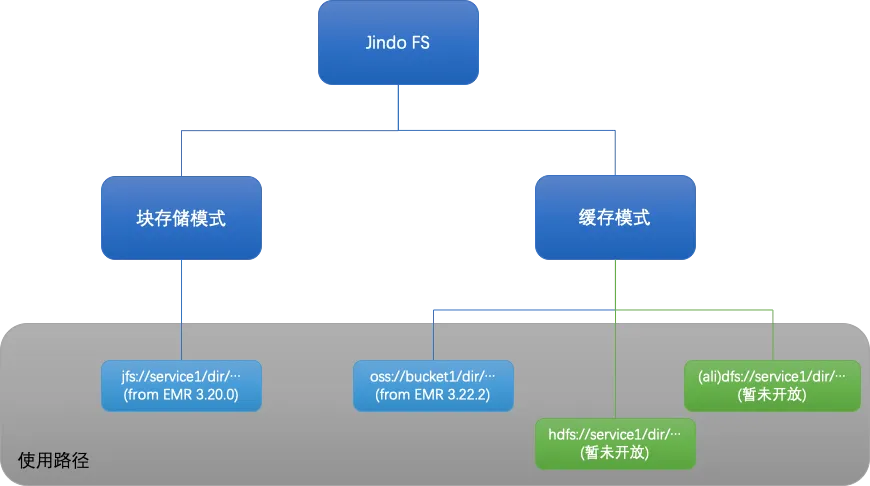
计算和存储分离是业界的趋势,OSS 这样的云上存储能力是无限大的,成本上非常有优势,如何利用 OSS 提供的无限存储能力,同时又高效地操作文件系统的元数据。JindoFS块存储模式提供了一套完整的云原生解决方案。

JindoFS 的块存储模式,在元数据上使用 JindoNameService服务管理 Jindo 文件系统元数据,元数据操作的性能和体验上可以对标 HDFS NameNode。同时,JindoStorageService 保障了数据可以始终有一份存在 OSS 上,即使数据节点被释放,数据也可以随时从 OSS 上拉取,成本上也可以做到更加灵活。
JindoFS 的块存储模式,也支持多种存储策略,比如,本地存两份,OSS上存一份;本地存两份,OSS上不存储;本地不存,OSS上存一份等等。用户可以充分利用不同的存储策略根据业务或者数据冷热进行使用。
缓存模式,正如“缓存”本身的含义,通过缓存的方式,在本地集群基于 JindoFS 的存储能力构建了一个分布式缓存服务,远端的数据可以保存在本地集群,使远端数据变成“本地化”。简单地描述JindoFS缓存模式解决的问题
就是“OSS / 远端HDFS已经有了大量数据,每次读数据的时候网络带宽经常被打满,Jindo FS 就可以通过缓存模式优化网络带宽的限制。”
“原来的文件路径是 oss://bucket1/file1 或 hdfs://namenode/file2,不想改作业的路径可以吗?”。是的,不需要修改。EMR 对 OSS 进行了适配(后续会支持远端 HDFS 的场景),可以通过配置的方式使用缓存模式。缓存对于上层的作业做到了完全无感。
但是缓存模式也不是万能的,为了保证多端数据一致性,rename 这种操作一定要同步刷新到远端的 OSS / HDFS,特别是 OSS 的Rename 操作比较耗时,缓存模式对rename这种文件元数据操作暂时不能优化。
在 2019 年的云栖大会上,EMR Jindo 的技术存储分离方案得到很大的关注,视频直达链接【云上大数据的一种高性能数据湖存储方案】
【EMR打造高效云原生数据分析引擎】后续我们也会在云栖社区和钉钉群分享更多的 Jindo 技术干货,欢迎有兴趣的同学加入 《Apache Spark技术交流社区》进行交流和技术分享。

本场景介绍如何利用阿里云MaxCompute、实时计算Flink和交互式分析服务Hologres开发离线、实时数据融合分析的数据大屏应用。
本课程由阿里云开发者社区和阿里云大数据团队共同出品,是SaaS模式云原生数据仓库领导者MaxCompute核心课程。本课程由阿里云资深产品和技术专家们从概念到方法,从场景到实践,体系化的将阿里巴巴飞天大数据平台10多年的经过验证的方法与实践深入浅出的讲给开发者们。帮助大数据开发者快速了解并掌握SaaS模式的云原生的数据仓库,助力开发者学习了解先进的技术栈,并能在实际业务中敏捷的进行大数据分析,赋能企业业务。 通过本课程可以了解SaaS模式云原生数据仓库领导者MaxCompute核心功能及典型适用场景,可应用MaxCompute实现数仓搭建,快速进行大数据分析。适合大数据工程师、大数据分析师 大量数据需要处理、存储和管理,需要搭建数据仓库?学它! 没有足够人员和经验来运维大数据平台,不想自建IDC买机器,需要免运维的大数据平台?会SQL就等于会大数据?学它! 想知道大数据用得对不对,想用更少的钱得到持续演进的数仓能力?获得极致弹性的计算资源和更好的性能,以及持续保护数据安全的生产环境?学它! 想要获得灵活的分析能力,快速洞察数据规律特征?想要兼得数据湖的灵活性与数据仓库的成长性?学它! 出品人:阿里云大数据产品及研发团队专家 产品 MaxCompute 官网
阿里云携手神州灵云打造云内网络性能监测标杆 斩获中国信通院高质量数字化转型十大案例——金保信“云内网络可观测”方案树立云原生运维新范式
2025年,金保信社保卡有限公司联合阿里云与神州灵云申报的《云内网络性能可观测解决方案》入选高质量数字化转型典型案例。该方案基于阿里云飞天企业版,融合云原生引流技术和流量“染色”专利,解决云内运维难题,实现主动预警和精准观测,将故障排查时间从数小时缩短至15分钟,助力企业降本增效,形成可跨行业复制的数字化转型方法论。
【10月更文挑战第8天】 云原生技术,作为云计算领域的一次革新性突破,正引领着企业数字化转型的新浪潮。它不仅重塑了应用的构建、部署和运行方式,还通过极致的弹性、敏捷性和可扩展性,解锁了未来计算的无限潜力。本文将深入浅出地解析云原生技术的核心理念、关键技术组件及其在不同行业中的实际应用案例,展现其如何赋能业务创新,加速企业的云化之旅。
从湖仓分离到湖仓一体,四川航空基于 SelectDB 的多源数据联邦分析实践
川航选择引入 SelectDB 建设湖仓一体大数据分析引擎,取得了数据导入效率提升 3-6 倍,查询分析性能提升 10-18 倍、实时性提升至 5 秒内等收益。
阿里云ACK One:注册集群支持ACS算力——云原生时代的计算新引擎
阿里云ACK One:注册集群支持ACS算力——云原生时代的计算新引擎
阿里云ACK One:注册集群支持ACS算力——云原生时代的计算新引擎
ACK One注册集群已正式支持ACS(容器计算服务)算力,为企业的容器化工作负载提供更多选择和更强大的计算能力。
本文介绍了云原生算力的进化,重点讨论了倚天710 CPU在大数据和视频转码场景中的应用与优势。倚天710采用ARM架构,通过物理核设计和CIPU加速卡优化,显著提升了高负载下的性能稳定性,并在实际应用中帮助客户实现了20%-40%的性能提升和成本降低。此外,文章还探讨了操作系统、编译器等底层软件的优化,以及如何通过龙蜥社区和阿里云平台支持更多应用场景,助力企业实现高效迁移和性能优化。
Serverless Argo Workflows大规模计算工作流平台荣获信通院“云原生技术创新标杆案例”
2024年12月24日,阿里云Serverless Argo Workflows大规模计算工作流平台荣获由中国信息通信研究院颁发的「云原生技术创新案例」奖。
在这个快节奏的数字时代,云原生技术以其灵活性和可扩展性成为了开发者们的新宠。本文将带你深入了解Kubernetes和Docker如何共同塑造现代云计算的架构,以及它们如何帮助企业构建更加敏捷和高效的IT基础设施。
如何在Aliyun E-MapReduce集群上使用Zeppelin和Hue
阿里云 EMR Serverless Spark:面向 Data+AI 的高性能 Lakehouse 产品
立马耀:通过阿里云 Serverless Spark 和 Milvus 构建高效向量检索系统,驱动个性化推荐业务
鹰角网络:EMR Serverless Spark 在《明日方舟》游戏业务的应用
千万级数据秒级响应!碧桂园基于 EMR Serverless StarRocks 升级存算分离架构实践
StarRocks + Paimon 在阿里集团 Lakehouse 的探索与实践
美的楼宇科技基于阿里云 EMR Serverless Spark 构建 LakeHouse 湖仓数据平台
阿里云 EMR Serverless Spark 在微财机器学习场景下的应用
阿里云 EMR 发布托管弹性伸缩功能,支持自动调整集群大小,最高降本60%


